Give to charity, get books you want
November 25, 2007
Many of you know that I’m on the board of three Internet-era charities, the EFF, Creative Commons and the Open Rights Group (UK).
I was thinking of what I could do to fundraise for them, and came upon this idea:
* for every $10 you commit to giving to one of my 3 charities, I’ll give you one of my mooch points, which you can redeem to get one book for free on BookMooch.
In this way, and this way only, people could “buy” mooch points, which I know other book swapping sites do, and some people on BookMooch have requested. One of the few prohibitions I’ve had on BookMooch is against the selling of points, because that could turn BookMooch into an eBay replacement, and not a friendly barter system. However, under this scheme, because the money doesn’t go to the person, but to a charity, I don’t think there is a problem.
I came up with $10 per point, because I’ve run the report of books swapped on BookMooch vs their current best price on Amazon, and on average a book traded on BookMooch is worth $11.
So, here is what I propose:
– any BookMooch member who wants to offer some of their points to help charity is welcome to participate in this
– if you are participating, please modify your bio to indicate what charities you want to help. Take a look at my bio as an example, or just copy/paste what I wrote, modifying it accordingly:
| <b>Give to charity, get books you want</b>
Until the end of 2007, I will give 1 mooch point for each $10 given to one of the charities that I am on the board of: the <a href=”http://www.eff.org/”>EFF</a>, <a href=”http://creativecommons.org/”>Creative Commons</a> and the <a href=”http://www.openrightsgroup.org/”>Open Rights Group</a> How this works: send your donation to one of these charities, and then email me a copy of the receipt, either as a scan, pdf or email. I will then use the BookMooch “charity” feature to send you your points. |
– Add a link your bio page on the “Give to charity 2007” page on the BookMooch wiki so that people can browse all the people making this offer
– this fundraising drive will end at the end of 2007
Have fun!
Here are links to each group’s giving page:
Away for a month
November 23, 2007
Tomorrow morning, I fly out of London and go back to my other home in California.
I’m moving home in 10 days, from Berkeley, California to San Rafael, California; from a suburban University town (Berkeley) to the middle of a state park. My plan is to spend half my time living in the hectic-but-amazing centre (note British spelling (grin)) of London, and then chill out until I nearly go comatose with lack of stimulation in the center (note American spelling) of a huge natural park.
What this means for BookMooch is that I’ll be on vacation from programming for about a month. No new features or changes, and the half-dozen or so small bugs outstanding will need to wait until the end of December. On the positive side, it means a month free of John-screwing-things-up, which I’m sure many of you will be grateful for.
I’ve actually been on a BookMooch holiday for the past 10 days, acting as a recording engineer for two different CDs, one of the JS Bach Sonatas for Violin and Harpsichord, and another of 19th century Fortepiano and Natural Horn (played by my friend Anneke Scott) including a drop-dead-gorgeous piece by the incredibly obscure composer “von Krufft”. Both will be on Magnatune in 6 months to a year (it takes a long time to finish a recording).
Personal Blog
If you’re interested in reading about my life outside of BookMooch (yes, it’s true, I occasionally do have a life outside of BookMooch), my wife keeps a great Blog of our life, at:
Mooch ratio calculation change
November 19, 2007
After a very long discussion on the blog I’ve now changed the way the mooch ratio calculation works.
The “mooch ratio” is the number of books you’ve given, vs books received, and currently at BookMooch you have to maintain a 5:1 ratio. The current discussion, not yet settled, is whether to lower the ratio to something like 2:1.
You can see your mooch ratio calculation by logging in, and then clicking on the “mooch ratio” link on the top right of the page, like so:
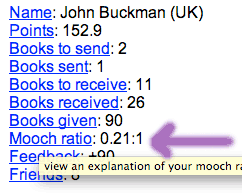
You can see the ratio for my UK BookMooch account now:
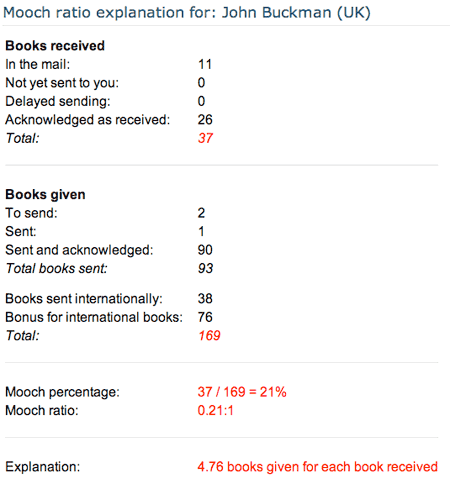
what’s new is that books sent internationally are now listed separately, and you get a bonus on your mooch ratio for them.
Each book sent internationally is counted 3 times: once as a book sent, and then twice more as a bonus.
The idea is that if you send a book internationally, you get 3 points, and you should be allowed to spend those 3 points.
I was looking at a table I made of people who keep their ratios at 3:1 or worse, and very few of them are consistent good BookMooch users, most tend to be people who gave a few books away, then got as much as they could get, and then abandoned BookMooch. I’m sure there are exceptions, but that is the generalization of what I saw.
So… take a look at your own mooch ratio, and see if you would be affected by a policy change at BookMooch, requiring (say) a 2:1 ratio.
I was also thinking of posting a list of all the members with a 3:1 or higher mooch ratio, so that people could take a look at real members and see if they think they’re being fair or not, but I don’t want to start a witch hunt either.
Idea for mooch ratio change
November 17, 2007
I’m thinking of changing the mooch ratio requirement from 5:1 to something much more strict, like 2:1.
The reason, is that I’m seeing a small number of people put massive inventories in, and then being about to keep pretty awful mooch ratios, because they have the points to do so from having listed so many books.
I don’t want to penalize honest moochers who send a lot of books internationally, so I was thinking of changing the mooch ratio calculation to give you 2 mooch ratio points for each book sent internationally. That way if you send out one book internationally, you can mooch two books and still have a 1:1 ratio.
This problem will get worse when big used book stores want to use BookMooch.
What got me thinking about this is my receiving today an email from a web-based used book store who wants to put their inventory of 75,000 books into BookMooch.
That would give them a massive number of points (7500 points), and allow them to get 5 books for every 1 they give away, under the current system. I don’t think that’s a good thing.
Changing the ratio requirement to 2:1 would largely close that loophole, while not punishing people who send internationally who have a slightly poor ratio under the current calculations.
Thoughts?
Some data loss, but stable for now
November 17, 2007
BookMooch came back up yesterday.
There was some data loss, namely 1/3rd of the members had to be restored from an 8 hour old backup, so their book transactions during that period were lost.
If you were effected by the data loss, please contact tech support and briefly explain your problem.
The good news is that in the two days of having BookMooch down, I changed the way the database works (this is for geeks only: using a “write-ahead transaction log”) and in theory, data loss from bugs should be a thing of the past.
This would be a good thing, so that a) my and my admins stress level can go down and b) I’m certain to introduce bugs in the future and when that happens there shouldn’t be any damage from it.
Note that right now I don’t have new books to BookMooch being added to the search engine, because I want BookMooch to be proven as reliable for several days, before I go mucking with it again. I’ll re-enable this when I’m confident there are no other problems.
Big BM back-end changes
November 8, 2007
A new version of BookMooch went up today, with some really big back-end changes.
Despite my testing, it’s only me doing all the work at BookMooch, so it’s likely there will be some bugs. Post new bug reports them here (as comments) and I’ll get to them quickly.
Here is what is new in today’s version:
– an option to opt out of related editions emails is now available, either as a click-through URL on the emails themselves, or as a enable/disable setting in your member profile page.
– an API for “pending action” has been added, allowing access to all the BookMooch workflow steps that are present in the “pending” tab, such as “delay” “send” “reject” “received”, etc… In addition, the API docs have been overhauled.
– the search engine has been rewritten from scratch: this is explained in greater detail below.
- I also fixed a big bug I found: previously, if you searched for two words, each one matching a different part, such as “card game”, the book “Ender’s Game” by Orson Scott Card would *not* be displayed, because no book was found where both words (“card game”) were found in the same section (ie, both in the title, or both in the author name). This was probably the biggest reason people had trouble with the search results, and this is now fixed.
- I’ve also made it so if you search for a username (ie, “johnbuckman”) the books in that user’s inventory are displayed in the search results (but only if no books were found with that word in them, so if somone’s username is “john” then the user’s books won’t be displayed, only the search hits for “john” will be).
Geeky details about the search engine rewrite
I’ve been concerned that “writing changes to the hard disk” would be the next limit that BookMooch would confront.
Let me explain: I currently have disk writes cached, writing them out to disk every 60 seconds. What concerns me is that my web server is regularly alerting me that the disk writes are taking a long time:

If a disk write takes 20 seconds to complete, and runs every 60 seconds, that means that every 60 seconds, I “store up” 20 seconds of changes. The worry is that if BookMooch usage goes up, I will “store up” more changes than I can write to disk in 60 seconds, and then I won’t be able to keep up. And then, BookMooch goes boom.
I needed to find out what most of the disk writes were, and if there was a way to optimize that.
I wrote a function to log all disk writes, the table name, and the number of bytes written. I ran the logging function on BookMooch for 24h, and here is what I found (column 1 is the table name, column 2 is the number of bytes written in 24h):
 |
You can see that the last entry is “search_asin”, which is the table that is the search index for books. That one table is responsible for 80% of the disk writes on BookMooch. Clearly, I needed to change that.
Before the rewrite, each row in the search_asin table looked like this:
|
|
Each word that ever occured in a Title/Topic/Author/Publisher had a row in this table, and that row listed the books that used that word, and where that word was used (ie, in the title, in the author name, etc)
This is a very space and speed efficient way of storing this kind of information. When a user does a single word search, BookMooch just needs to do one database row fetch, and all the books matching the word are found.
Unfortunately, this efficiency came at a high price: adding books is very inefficient.
For example, if I add a book whose title is simply “Photography” and whose ASIN is 0330284711 I first fetch this entire row:
|
|
I add the ASIN to the Title section of the row, and rewrite it out:
|
|
that’s fine for words that don’t happen often. However, words like “book” occur VERY often (over 300,000 books mention it) and so every time a new book is added that uses the word “book” in its title or description, I have to read and write back 300,000 ASINs. At 10 bytes each, that means 3 megabytes of data that have to be written to the disk.
So that’s why search_asin is responsible for 80% of the disk writes — the current method was very in-efficient at adding new books.
I’ve rewritten the search table to use a new method. Now, each row look like this:
|
|
when you search for the word Photography, the database is asked to return the first row that is greater than “{k Photography}”, store the value for that row (which is the ASIN) and then find all the other rows that match “{k Photography}”, and return all the values found. Because the database stores its keys in sorted order (it’s what’s called a B-Tree, or balanced tree) this actually works.
This greatly improves the efficiency of adding books to the database, because each word for each book in each match (title / publisher / author, etc) now gets its own row, and there is no need to read-in then write-back the same data.
However, this change in algorithm does come at a price:
1) the search_asin table is now 10x larger (from 339mb to 3.0gb) because of the duplication of key data. This makes the in-memory cache less efficient. However, since most words in the index are probably never searched for, this probably doesn’t matter.
2) searching is now slightly less efficient, since many rows need to be read, rather than just one row. However, since the database is largely in memory, and I wrote this search function in C, the difference in performance seems minimal.
On the positive side, the last time I rebuilt the full text index on BookMooch, it took 12 days (with the old system). With the new system, it took only 5 hours on my iMac, so clearly the new method is much more efficient at adding books.
The “browse books by topic” feature had to be rewritten too. You can see in the “database write log” above that “search topics” is the 3rd most written-to table. It used to use a similar algorithm to the search_asin table, and now they both use the same (new) technique.
However, this also came at a price, namely that the old browse topics page:
 |
used to show how many books each topic had. This actually wasn’t that useful, because the number displayed was the number of books in the database with that topic, and not whether any of those books are actually available.
The new browse topics page just displays the top topics based on books available. I made this list by hand based on the number of books actually available for each topic, so it’s probably a more helpful list:
 |
Unfortunately, you no longer can view the “top 1000” topics. Sorry: the new “browse topics” database table structure just doesn’t permit me to generate that information in any sort of efficient way (there are 260 million rows in that table, it takes hours to go through it)
Noise Words
Most full text algorithms try to not index “noise words” such as “the” “and” “or”, etc… The thinking is that
Instead of just guessing what the most common words are, I wrote a program to count them. Here are the top 30 most common words to appear in a book title, author, or publisher, along with how many books at BookMooch feature that word:
|
|
You can see that some of the most common words, such as “science” and “history” are hardly “noise”. But, if you search for “the science of history” you are asking BookMooch to look through:
|
|
Yes, that’s a million book matches for those words. Ugh. On my iMac, that search takes about 5 seconds of one CPU. That’s pretty slow.
For now, I’ve decided that because these common words are hardly “noise” (they are actually quite meaningful) that I’m leaving them, so that for instance a search for “the classics” does include the word “the” as a required hit in the search results.
Other database changes
If you look back to the top of this blog entry, at the list of tables that get the most writes, you’ll see that the top 3 are
|
|
if you remove “search asin” and “search topics” tables from the stats, since presumably they are more write-efficient now, that leaves the “userids” table.
The userids table, like most tables at bookmooch, stores most of its data in a single row, in an alternative key/value structure, like this:
|
|
this is very efficient for data reading, since all the information on a member is loaded all at once, in a single row. It’s also very disk space efficient.
However, if there are fields in the user record which are updated frequently, this means reading-in and writing-back the entire user record.
I wrote another database log function to track which fields in the userid table were being changed frequently (note, when several fields are listed below, it’s because they’re being updated simultaneously):
 |
The top two are the “wishlist” and “lastnow” fields, but there are lots of others as well. The “lastnow” simply tracks the time you last logged in, and is a fairly minor feature, but it’s responsible for 20% of the writes to the userid table. So, I decided to move that field out to its own table, which should make updating it much more efficient. As to the other fields, well, they’re a lot more work to optimize, as they’re widely used inside BookMooch, so I’m putting rewriting those off for another day.
That’s it for this blog entry! I hope some of you found this in-depth technical exposé interesting!
BM roadmap for the next 2 months
November 6, 2007

Here is what I’m currently working on for BookMooch:
– The next update (in a few days) will be a big back-end database change, and I’m hoping to get all the bugs worked out, and I’ll only do the update right after a backup in case there’s a problem.
– The “search engine” had to be completely rewritten, as my measurements found that it was responsible for 80% of the disk writes. I also found and fixed some big bugs with the current search engine in the process so the search results should be much improved.
– BookMooch is currently spending about 15 seconds writing to the disk for every 60 seconds elapsed. What that means is that if I don’t really improve disk writing efficiency, I’ll have big problems when the site grows more as I won’t be able to keep up.
– Next after the database change is finishing up the new forums feature & redoing tech support so that anyone who wants to can help answer questions.
– Once that’s all done, I’m writing BookMooch plugins to Facebook and Open Social and adding BookMooch to Google Books, and I expect those changes will bring it a lot more new users. I want to make sure we’re ready for the growth before I cause it.
– I’ve also had to change a lot of the code in the “mooching” and “pending” process, to build an API on top of it now that I have my first real user. http://www.bookswim.com/ wants to automate their use of BookMooch, to offer our users the books they have no demand for, and get books that they need. Again, I’m testing a lot, but there’s a possibility I’ll introduce some bugs, and I’ll fix those right away.
– I will probably soon have to institute a “reservation” system for popular books, where you can’t mooch a book that many people want until you’ve received their wishlist notification, or all the notifications have gone out. The reason, is that with the new API, it’ll be possible to write an “auction sniper” to always obtain every book by constantly checking to see if a book is now available. One can do that with RSS too, by tying an RSS feed to an auto-mooch program (once I speed up the refresh rate on the RSS feed, they’re once-per-hour now). Probably, the way this will work is that you’ll be able to mooch a book once you receive your wishlist notification email, but not before, and if the book isn’t on your wishlist, you won’t be able to mooch it until everyone who has that book on their wishlist has been notified. I’m still thinking this one through, and will bring it up for full discussion when I get closer to having the time to implement it.
ps: the next update will let you opt-out of the new “related books wishlist notification” feature.
Tweaks
November 4, 2007
Some small tweaks:
Related edition notifications: in the email notification you get from your wishlist, when a related book is available, the email message subject and body now indicate that this is a related edition. Here are the changes:
| Subject: BookMooch related edition on wishlist: “You Don’t Need Meat” : Peter Cox
A related edition of a book on your wishlist is now available on … To stop receiving email notifications, move this book to your … |
“Details” from Amazon: a “details” button appears on every book resulting from an Amazon search. Click this button, and you’ll see the full book details. In the background, this book has now also been permanently added to the BookMooch database, so this is also a handy way to tell a friend about a book and give them a BookMooch url. Also, clicking on the book cover graphic on all Amazon searches now goes to this detail page, whereas previously it would sometimes show you a large book cover, other times add the book to your inventory, which was confusing.
Amazon info button: previously, the “amazon info” button appeared on every book details page. On books that had been hand-entered, the button wouldn’t work right (since that book wasn’t at Amazon). Now, the “Amazon info” button doesn’t appear if the book was hand-entered.
Charitable mooching: the email notification you receive when a charity mooches from you now indicates that this is a verified bookmooch charity. Also, the email from a charity’s mooch no longer warns that they are “MOOCHING, NOT YET GIVING” since that’s ok for charities to do.
Look up an email address: the “look up a user from an email address” feature wasn’t working correctly for the members that had several email addresses entered into BookMooch (which you can do, if you use a comma between your email addresses)
Closed account backups: when an account is closed, BookMooch automatically backs up the inventory/wishlist/savelater/friends that closed member had, so that an admin can restore that data if the account was mistakenly closed.
Another round of features
November 2, 2007
A few more significant changes in this blog update.
Site Map
I have made a “table of contents” of most of the BookMooch web site. If you are not a member (ie, not logged in), you get a different site map than if you are logged in.
The site map for non-members is in the Main “About” tab at
http://bookmooch.com/about/sitemap
The site map for members is in the “About” section (which you reach from the main member menu), as is at the url:
http://bookmooch.com/m/sitemap
Take a look, maybe you’ll find some features you were not aware of.
Mooch Ratio Explanation
From your “bio” page, if you click on the words “mooch ratio” you will now see a “Mooch ratio explanation” page
People have always been confused about how this number is calculated, so now the formula is shown.
In building this page, I myself got all confused about how this worked, and actually rewrote the code to make it clearer, so that I could also explain it.
It’s entirely likely that, in rewriting the mooch ratio calculation, I didn’t get every detail right. The good news is that now people can see how the number was arrived at, and point out any mistakes I’ve made, so hopefully I can benefit from the collective scrutiny of the mooching members to find my mistakes for me.
At the bottom of the explanation, I put the ratio into a sentence, which hopefully makes things a bit clearer:
| 4.16 books given for each book received |
Note that the sentence structure is reversed if you mooch more than you give:
| 1.81 books received for each book given |
Wishlist notifications and related editions
Emailed wishlist notifications now send to people who have related editions of that book on their wishlist as well.
This can sometimes mean that you’ll get a wishlist notification for a related edition that you don’t want, such as a translation of that book into another language, but most of the time this should be helpful.
This means that most of you will no longer need to add all the related editions of books to your wishlists to get the notifications.
The “Added to wishlist” message makes this feature change clear:
| You will receive an email notification when this book (or a related edition) becomes available. |
Smart redirecting to non-member pages
I mentioned in a recent blog entry that the pages under the /m/ directory at BookMooch now require you to be logged in. I also said that if you sent a URL to someone, please send the non-/m/ version, ie
NOT this:
| http://bookmooch.com/m/inventory/buckman_ca |
but this:
| http://bookmooch.com/inventory/buckman_ca |
However, since that blog posting, I found a way to automatically redirect people who hit the Cancel or Escape key, when asked to log in if they go to those pages, and they are then automatically redirected to a non-member version of the same page. This is currently in place for “wishlist”, “inventory”, “pending”, “detail”, and “friends”.
This trick works for people using these web browsers:
This trick does not work for these web browsers:
Safari/OmniWeb both display a blank page if the user chooses to cancel a “HTTP Login” dialog box. I’ve filed a bug report with OmniWeb, to see if they’ll fix their behavior, but I don’t think I will bother trying to tell Apple about their bug (I can’t figure out how you would even report such a thing).
FYI, for geeks, this trick involves putting a META HTTP-EQUIV=”Refresh” html command in the HTML document that is returned with the “401: WWW-Authenticate” response from the server. IE/Firefox/Opera all display this document if the user chooses not to authenticate, while Safari/Omniweb choose not to display it.
Bug fixes:
- widgets for mooches should only show successful mooches
- the “show a random set of my wishlist books” widget now works correctly, previously it was showing books from your inventory
